Python Django+SQL+Pandas+Pyecharts自建在线数据分析平台(七)
文章来源:Python Django+SQL+Pandas+Pyecharts自建在线数据分析平台(一)
作者:ccpic
感谢:感谢作者 ccpic 分享的优质内容,本网页主要用于学习知识的存档备份,欢迎点击原网页支持作者。
(一)需求分析&技术实现
(二)初步搭建Django环境
(三)页面布局&Django模板
(四)SQL+Pandas初步处理数据
(五)前端表单交互
(六)Ajax异步传参与加载
(七)前端数据格式的处理
(八)DataTables接管前端表格
(九)Pyecharts实现交互图表
(十)静态图表的展示
(十一)“导出数据至Excel”功能
(十二)添加和配置缓存
(十三)用户登录系统
(十四)部署Django至生产环境
从本章开始,系列文章进入数据可视化的部分,我们从一个比较小的话题前端的数据格式开始。
其实本章的位置在其他任何Django系列教程里是要留给**自定义tag和filter(标签筛选器)**大谈特谈的,但是我们的项目舍弃了Django ORM又大量使用了AJAX,自然前端模板很难用到渲染的tag,tag filter也就无用武之地了。
但还是简单介绍下,毕竟这也是Django的特色之一。我们在前端其实还是用过一次tag filter的,是在第五章前端利用字典循环创建多选框时,有如下语句:
<select name="{{ value.select|add:"_select[]" }}" id="{{ value.select|add:"_select" }}" multiple="" |
其中的双大括号部分,就是一个tag+filter的组合,竖杠后面的部分是竖杠前方tag的filter,冒号后面部分则为这个filter的参数:
{{ value.select|add:"_select" }} |
这个语句的作用为,对value字典里的select的值与”_select”做字符串拼接。
可以看出filter在Django里的定位是:
- 本质上是一种函数
- 用于修改后端数据在前端的呈现方式
- 不对数据做任何永久修改
- 任务相对简单直接
这个定位和数据分析平台对数据格式展示的严格追求是不谋而合的,又比较简洁有效。在有条件应用Django tag filter时应该尽可能地使用它,尤其当Django自带的filter无法满足你的时候,可以自定义filter。
本章我们的目标之一是给后台传来的market_gr变量在前端显示时转换为“保留一位小数的百分号”格式。假设我们在前端有一个{{ market_gr }}的tag占位符,我们可以自定义一个filter轻易做到这一点。
首先,在app文件夹下和templates平行的目录创建一个文件夹templatetags,并在该文件夹中新建两个.py文件——__init__.py和tags.py。此时的项目文件夹结构应该变成了这样: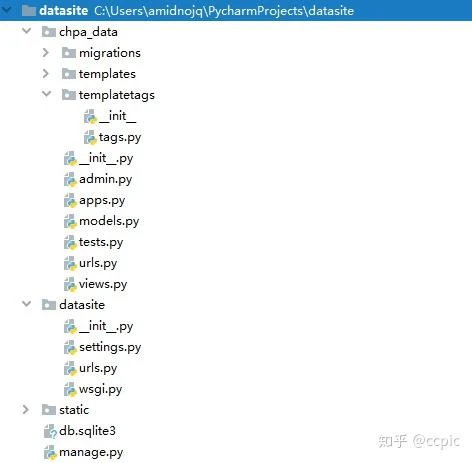
再修改工程settings.py文件
在TEMPLATE.OPTIONS里加入libraries参数,并指向之前创建的templatetags文件夹内的tags.py:
'libraries': { |
回到templatetags文件夹,其中__init__.py文件确保目录被视为一个Python包,可以保持为空。在tags.py里编写我们需要的filter方法。比如一个把数字转化为百分号的函数:
from django import template |
此时把前端模板文件里要加入:
{% load tags %} |
再把
{{ market_gr }} |
改写成
{{ market_gr|percentage:1 }} |
即可在前端显示时把任意float以“保留一位小数的百分号”的格式显示。
除了自定义filter,同时也推荐大家试试看Django自带的humanize包内置的filters,这里不展开了~
这时候问题来了,我的market_gr在现在的版本是用AJAX异步加载的返回里调用的,没法应用Django tag。这时教条地说,应该考虑前后分离的问题,在前端用JS完成数据的格式化。主要因为涉及到数据复用但格式不同的问题。
实际上我尝试了2种做法。
JS转换为百分数的例子,编辑前端filter.html模板:
<script type="text/javascript"> |
后端views.py转换百分数的例子:
def kpi(df): |
这里可以很明显看出后端调整格式的优缺点,优点是可以利用Python语法的便利性一行代码解决问题。缺点是输出的类型有可能变成字符串,导致前端后续一些操作更加麻烦(比如上方代码块中根据返回数据判断的条件语句)。而前端一些js操作html的便利性又是后端无法代替的。
但有时后端修改格式也是必须的,比如我们的表格ptable是用整个df.to_html()直接渲染的,前端修改格式就会麻烦得多。
此时有一种利用df.to_html的formatters参数专门为表格调整数据格式的快速方式,且该方法可以复用到很多其他的pandas表格输出结果上。
def query(request): |
此时的前端表格已经格式化了: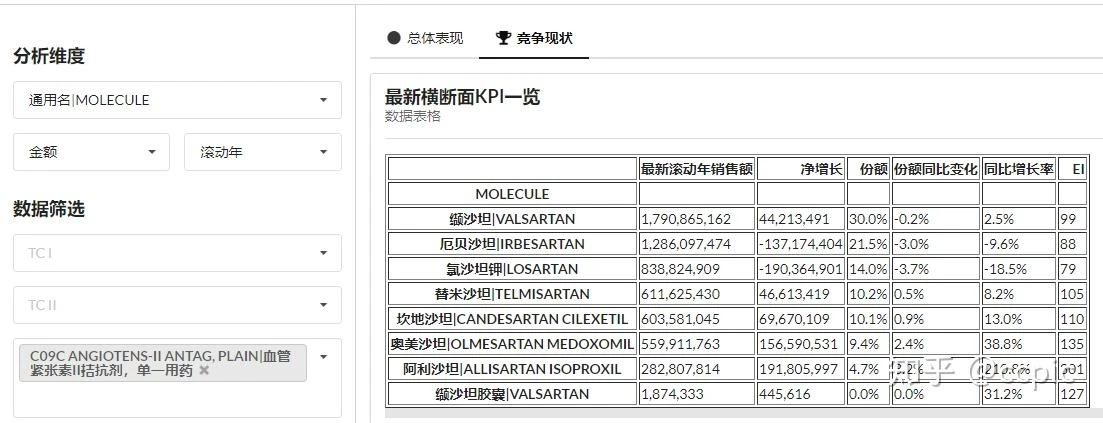
而要达到上方20行简单Python语句就能达到的效果,用JS重构必须付出数倍的努力。
所以这些涉及展示的非核心问题,在不是硬性要求前后端分离的场合,我最后的结论是——就八仙过海各显神通好了。